The Demo Gap: Why LLM-Powered Products Stall Between “It Works” and “It Ships”
WHY I’M WRITING THIS
I’ve been CTO of an AI company for six months following two decades in product and engineering at leading tech companies (TripAdvisor, DraftKings, Uber). I spend a lot of time talking to counterparts at major B2B software companies. Collectively, we find ourselves returning to the same questions: What will get us to the colossal AI launch that the market demands? We can build a demo that looks incredible. We know the capabilities are real. So what is it that will get us to that next level?
AdeptID builds AI in three ways. First, we build AI as a SaaS product for HR systems. Second, the AI we build is used by our own end users in the healthcare workforce space, specifically hiring managers and healthcare professionals. Third, the AI is used as the tool that our internal healthcare staffing recruiters live in day in and day out. Our three-pronged use cases provide us with the ability to look at the question above from multiple angles.
Others have covered the engineering debts between pilot and production (Talby). What is less covered is the strategic layer. Here, we’ll uncover the architectural choices and market economics that product and technology leaders need to understand if they want to harness the power of this new development era, all the while, accelerating the build of marketable products.
THE THREE PATHS IN AI PRODUCT SPACE
The AI landscape is consolidating around three distinct bets. Foundation Capital frames them as three waves: wrappers, AI-native, and agentic. That is great framing to consider the progress but also a bit consultative for my taste. There is another, more practical dimension. Instead of asking which era are we in (and how do I prove to my peers I’m ahead of them), ask which path are we on, and did we choose it deliberately? Most importantly: will it get the business to its goals? It isn’t about the buzzwords; it’s about actually shipping.
When you are considering a project with a meaningful AI component, you have three paths to choose from:
Path 1: Integrate Directly with a Foundation Model
The labs and their tooling, evolving fast: APIs, fine-tuning, long context, multimodal. Path 1 is wiring one of these models into your product yourself using your own prompts, data layer, and glue code. The models are fantastic and the tooling is effective. The bet is that general intelligence, called directly, is enough.
Can you solve your problem by integrating directly with an existing foundation model?
Path 2: Buy a Domain-Specific Wrapper
Pay a company whose entire product is that integration, tuned for your domain: a system prompt, a RAG layer, and a UI on top of a foundation model, sold to you as a finished tool. Where most of the current “AI product” market lives. Fast to adopt, and facing a hard moat question: if the model keeps getting better, what is the wrapper selling? Either you are buying an API/MCP or, more likely, an AI-built UI sitting on top of this layer that makes it look “complete”.
Can you buy a product from a company that has already built that integration for your domain?
Path 3: Special-Purpose Models
When people hear “small models” they picture the weaker end of the capability spectrum. That’s outdated. A purpose-built SLM today is more capable than many of the frontier LLMs from two years ago. Microsoft’s Phi-3, a 3.8B model that runs on a phone, scores 69% on MMLU, on par with GPT-3.5, and the research literature now treats domain-specific small models matching or beating general-purpose LLMs on specialized tasks as an established finding. The tradeoff isn’t capability anymore, it’s operational: SLMs are harder to tune, host, and maintain than calling an API. That’s a real cost. But for teams that can absorb it, the performance-per-dollar at scale is hard to ignore. It also requires a Science team to understand and reason about the performance and applications. Like Paths 1 and 2, you’ll usually consume this as an API or MCP, but what sits behind it is fundamentally different.
Do you need a model purpose-built for your domain to clear your cost, latency, or compliance bar?
These models have a lower capability ceiling than a frontier LLM, but are more efficient when it comes to cost, latency, and predictability. This infrastructure doesn’t make the noise of a frontier launch, but investment is strong where expertise and precision matter, increasingly because of a factor that hasn’t gotten enough attention: compliance.
Regulated industries like law and healthcare can’t send data to a third-party API and call it done. HIPAA, SOC 2, FedRAMP, and data residency require models you can control and explain. They need intentional compliance features that can’t be baked into a light wrapper on a foundation model. As Talby notes, the architectural choices that satisfy regulators are also the ones that win on cost and latency at scale.
THE THREE FALLACIES OF “BUILT HERE”
Let’s walk through a scenario.
The demo came to life in under one week. Imagine what we’d have in three months.
Becoming a foundation-model lab yourself is off the table: you can’t outspend a two-horse race. So the real question is how you build on one. The three fallacies below hit everyone who relies on a foundation model, whether you integrate directly (Path 1) or buy a wrapper (Path 2). Path 3 is the only way out.
Fallacy 1: “Let’s not worry about scale yet; let’s launch quick and iterate”
Token costs have fallen significantly. It’s easy to assume they’ll continue to fall, and that unit economics aren’t today’s problem. However, costs may not continue to fall. Certainly, they won’t fall uniformly (more on that in Fallacy 3).
And unfortunately for product teams, cost isn’t the first problem you hit. The first problem your team hits is capacity. Rate limits are a hard ceiling on what your product can do, set by someone else and adjusted without warning. At a meaningful production scale we’ve seen less than 25% of API calls succeed during peak hours leading to increased latency as we retry over and again.
A system that works in a demo, works in beta, works at low volume, and then starts dropping three out of four requests in production is not a scaling problem. It’s an architectural problem that has always been there, just invisible until load exposed it. Reserving guaranteed capacity isn’t the escape hatch it sounds like: below seven-figure spend it’s simply not as advertised, and constrained GPUs squeeze the startup and mid-market hardest.
The specific trap: systems built for low volume often use frontier models because it “doesn’t matter.” At 1,000 queries/day, GPT-5.4 at $15/1M output tokens costs ~$150/month. At 10M queries/day it’s ~$150,000/month. Same code, same architecture, 1,000x more volume. If you can even get that many calls to succeed!
Fallacy 2: “The Foundation Model Will Get Better”
It will. That’s not the problem.
The problem is the shared performance ceiling. When you build on a foundation model, your performance ceiling is set by that model, and so is your competitor’s. If GPT-5.x scores X on your task today and your competitor also uses GPT-5.x, neither of you has an advantage. You’re both paying for the same intelligence.
Talby documented this in regulated industries as early as 2024: on structured extraction tasks, smaller domain-tuned models consistently beat frontier LLMs at a fraction of the cost and latency. Recent work bears this out: a domain-trained legal model beat five frontier models on contract extraction while cutting cost 78 to 97%, and small fine-tuned models rival much larger LLMs on entity recognition. The general model handles natural language well. It doesn’t handle your domain’s edge cases, your terminology, or your definition of a correct answer.
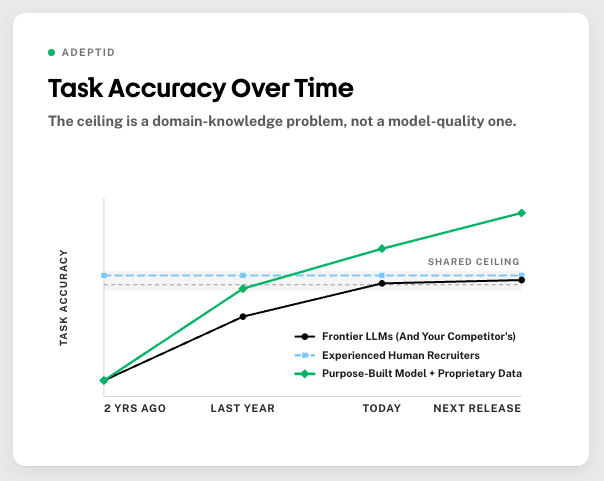
We hit this on one of our core prediction tasks: given a resume and a job description, will this candidate get an interview? When we benchmarked across frontier models and compared against experienced human recruiters, performance converged. Models and humans land at roughly the same accuracy ceiling. The next GPT release doesn’t break through it. Neither does switching labs. The ceiling isn’t a model quality problem, it’s a domain knowledge problem. Breaking it requires proprietary training data, domain-specific fine-tuning, and signals a general model was never trained to look for.
Fallacy 3: “Token Prices Will Keep Falling”
The demo was cheap. Three months of building will be cheap too. By the time you’re at scale, tokens will cost nothing. This is the most seductive version of the fallacy, and the hardest to argue against in a planning meeting.
The price compression from 2023 to 2025 was real: a 94.5% drop in average frontier output prices. It made building on LLMs look economically inevitable. But the curve did not keep bending the way everyone extrapolated.
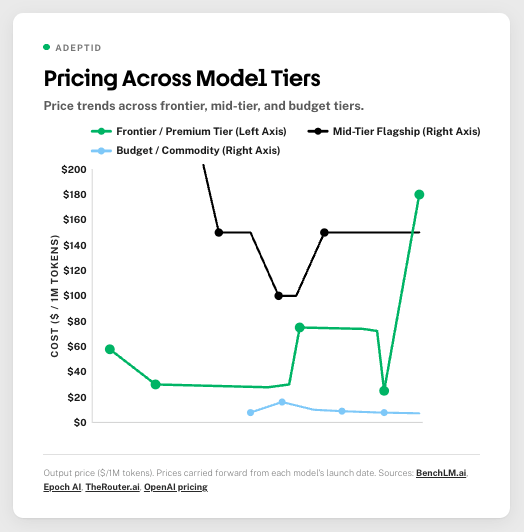
The story isn’t “prices fell.” The market split into two. Budget and mid-tier models kept falling: commodity open-source, flash-class inference, batch processing. The frontier tier went the other way. GPT-5.5 launched in April 2026 at $30/1M output tokens, double its predecessor from six weeks earlier. The labs found product-market fit at the high end and are pricing accordingly.
“Frontier model now, cheap model later” is not a straight substitution. A cheaper model in 18 months may not do what the frontier model does today. If your product depends on that capability, you’re either paying the premium or rebuilding.
The economics that made 2023-2025 prices possible were partly lab-funded market development: customer acquisition at a loss to build the ecosystem. That era is maturing. Even the optimistic industry projections, another ~90% drop in inference cost for trillion-parameter models by 2030, don’t tell you which tier captures those savings or which providers are still standing. Talby noted in 2024 that at millions of records per day, specialized models on your own hardware are 50-100x cheaper than frontier API calls. The math hasn’t changed. The scale at which it bites has only gotten lower.
“We’ll build on a frontier model now and the costs will work out” is a forecast, not a plan. Model it before you bet the roadmap on it. Consider: would your demo still look as good if you used a Turbo model or Haiku? If not, maybe you shouldn’t assume it will make it to production.
COMING NEXT: INGREDIENT SOFTWARE AND BESPOKE MODELS
The companies getting this right aren’t choosing between “use LLMs” and “don’t use LLMs.” They’re treating foundation models as one ingredient in a stack that also includes purpose-built models optimized for cost, latency, and recall on specific tasks. Talby calls this the “composition problem.” We’ve been calling it ingredient software. You are going to use LLMs, and you are going to use them a lot. What stack do you need underneath them to get the highest benefit from them while also building a marketable, performant product in three months?
Search is the clearest example. LLMs are good at query understanding, result summarization, and reasoning over a small candidate set. They are not good at first-stage retrieval over millions of documents at low latency. The right architecture uses both: a purpose-built retrieval layer that narrows the candidate set, and an LLM layer that reasons over what survives assuming it’s a small set. More than a couple hundred results and you’re back in all the traps above. That is why at AdeptID we have a combination of “old-school” information retrieval (using new school vector embeddings), SLMs, and LLMs to not only break the performance ceiling but do it at useful unit economics, all packaged as convenient APIs/MCPs that make them easy to implement in a composable way.
In this series of blogs we are going to dig deeper into the science, compliance, and usage of this approach.